on
NewTable分组功能
不好意思,我又来了,又来说NewTable了(忍耐
这次想分享一下NewTable的分组功能实现方式。
这篇读完可能会觉得NewTable的分组功能全是骚操作(也没有那么骚),为什么呢?那就得long long ago…(不是
分组功能的前因后果
分组功能想法的萌芽据我所知萌发在NewTable刚诞生之际
那个时候在写NewTable的时候,格局小了,完全没有考虑过会出现分组这样的需求
如果看过上一篇NewTable技术说明的话,会明白NewTable的绘制都是通过绝对定位"贴"上去的
每一行,因为是定宽,是有规律的,所以计算每一行的位置很简单。
但是,因为分组的组头和组内数据行高是不一样的,这样就把之前存在的规律打破了,绘制整个NewTable中的每一行,无法遵循某种规律快速的计算出每一行应该贴在哪里。
所以NewTable的分组功能,要面临的一大难题就是如何绘制。
具体实现
那么到底如何实现的分组功能,接下来就将分组功能分为几个重要的子功能展开详述。
该如何绘制
在分组功能的前因后果中提到了,分组功能的第一个困难就是因为分组头与分组内容行高不同导致无法运用其本身存在的固定规律去绘制,那么现在该如何去绘制呢?
NewTable技术说明中有提到自适应高度模式下NewTable的绘制方式
因为自适应高度下,每一行的行高是不固定的,所以要做的,就是生成一个行下标与当前行距top = 0的映射关系。
那么分组的绘制能不能使用这种方式呢?

答案是肯定的,能用!
BUT!!!!!!
虚拟怎么办???????????
虚拟怎么办???????????
虚拟怎么办???????????
行高自适应当时做出来就是不能虚拟的啊!?!!

BUT * 2!!!!!!!
分组虽然有一种把固定行高规律打破的表象,但是其本身还是有规律可循的。
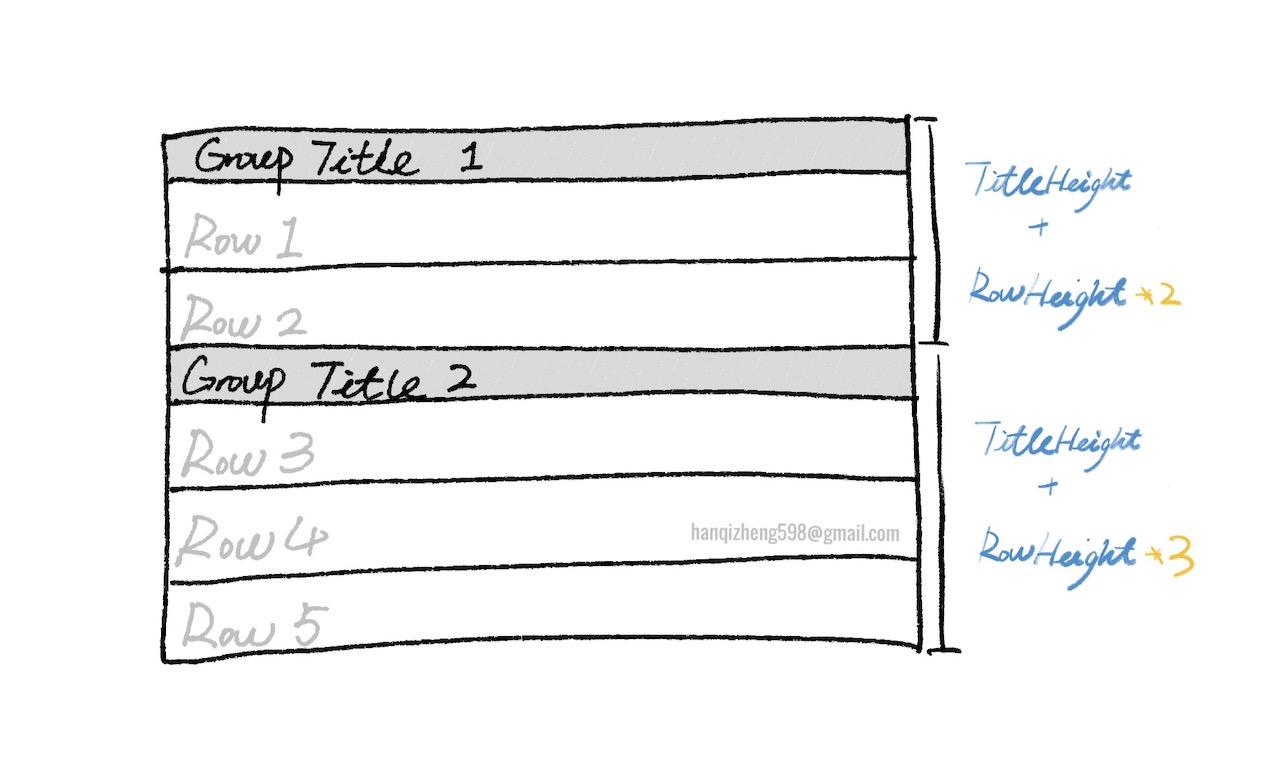
分组头的行高我们是知道的,是固定的。行高也是知道的,是固定的。
我们仅需要在渲染前知道 当前行之前有多少行是数据,有多少行是组头,就能计算出当前行距离top = 0的offset了。
所以我们要做的第一步就是把分组的数据groupRows拍平!!!!
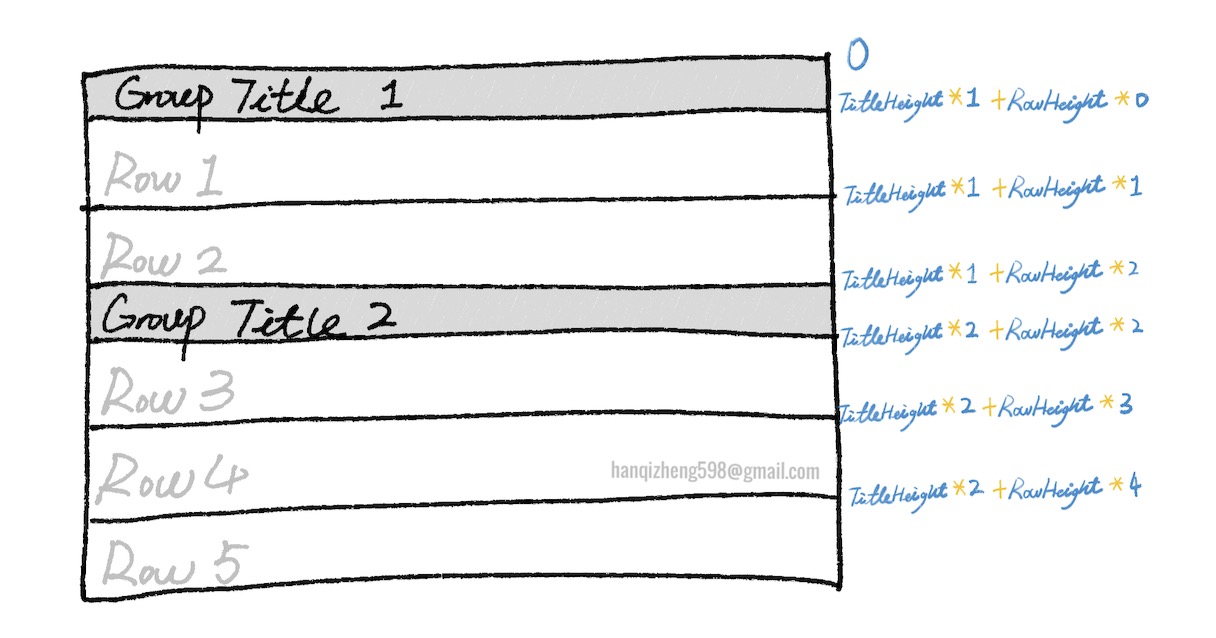
图中给出了具体的计算方式,但实际上代码中的体现,仅是在构建映射关系时,offset的累加过程中加一层判断,用于判断每一次offset的增量是分组头高度还是行高。
而且这样的计算方式其实是有迹可循的,所以能直接在render前就根据props来计算出所需要的数据。
而且拍平以后的绘制方式,有一个最大最大最大的好处,就是想无条件享受之前NewTable的TableRow所有的绘制逻辑。
这样也避免为了写分组模式而重新再写一遍NewTable的惨剧。
老生常谈的虚拟 - 分组模式下该如何虚拟
上一小节有说到为了绘制把数据拍平了。这里就不得不说一句,拍平的另一个好处就是,让虚拟变得容易一些。
虚拟的方式是将横向虚拟的function进行了扩展,因为分组模式的虚拟与横向虚拟非常类似。
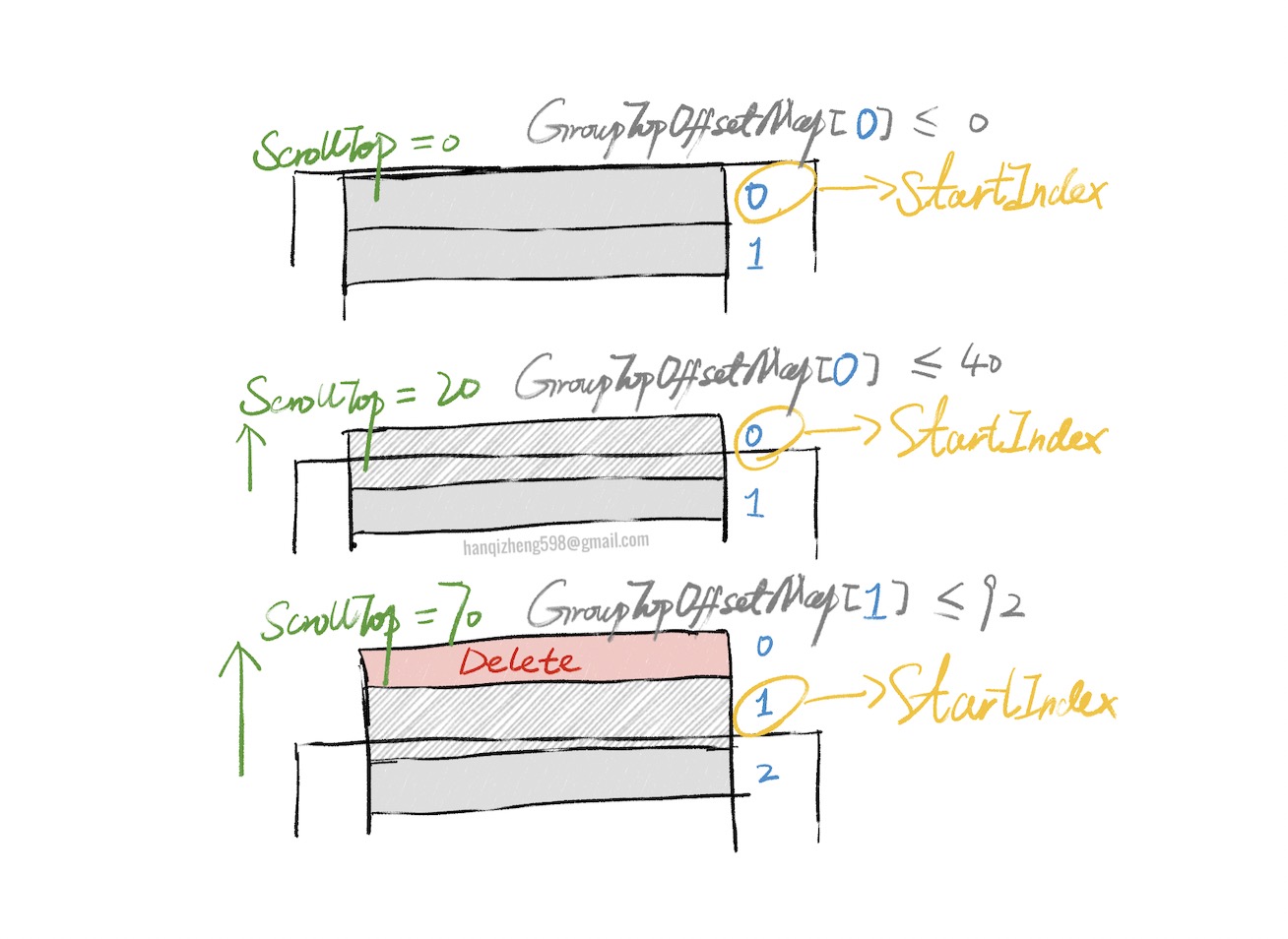
如上图所示,根据currentScrollTop与GroupTopOffsetMap中每一个数值进行对比,找到目标数值所对应的拍平后的数据中的index就是虚拟化截取的起点。
终点的寻找方式基本一样。
具体可以参考NewTable技术说明
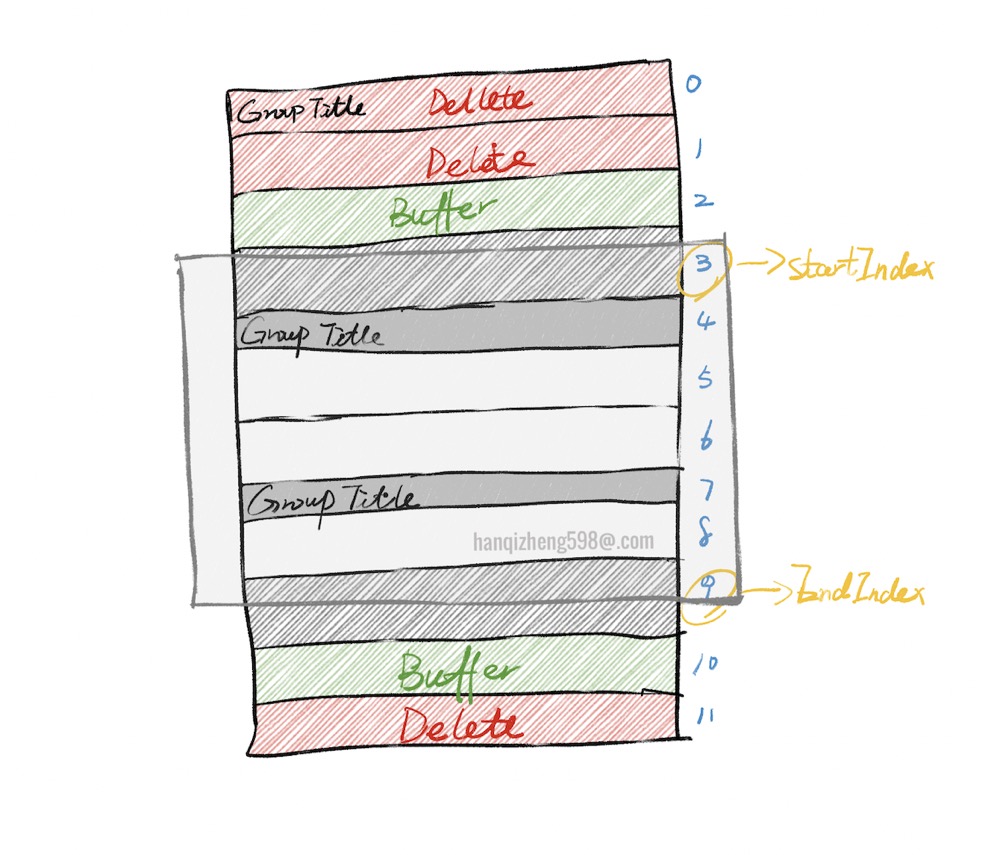
整体而言就是在数据拍平之后,处理方式与原来的NewTable一致。
为了吸顶效果的妥协
吸顶效果是遇到的又一个坑。因为在最初写好虚拟之后,其实绘制起来是完全与之前NewTable的方法一致的。也就是一行一行的画,只是每一行画的内容不相同罢了。
但是吸顶效果,要求随着上下滚动,分组的交替效果要有一种组头之间的推动关系。
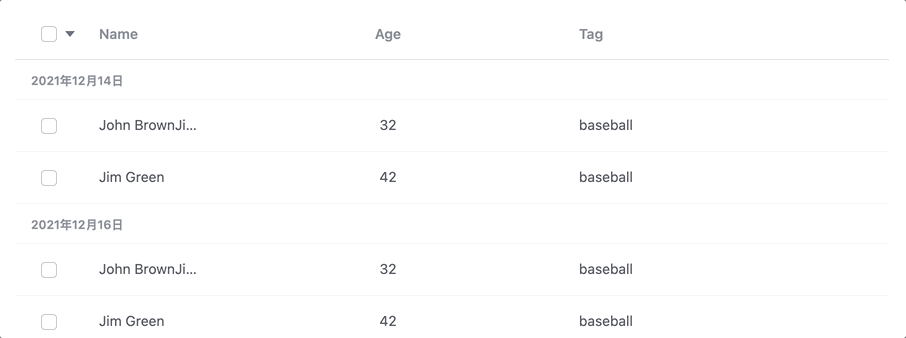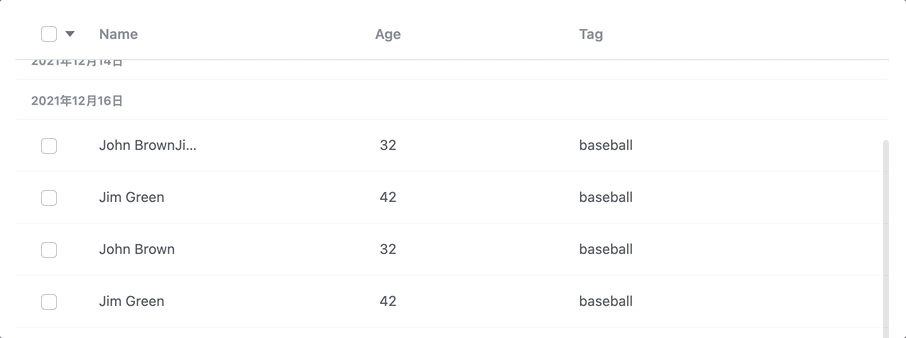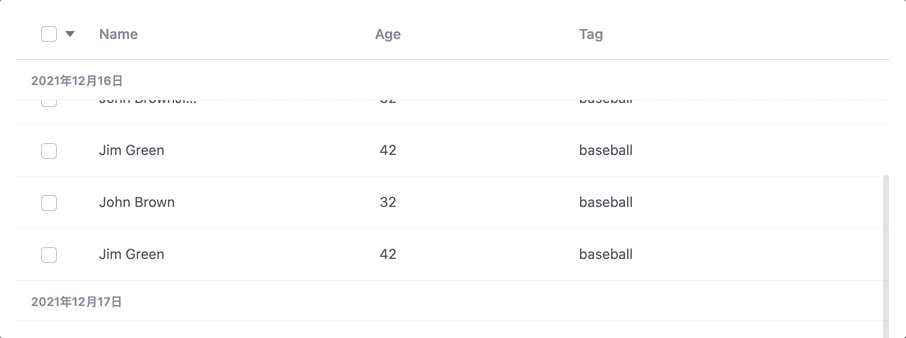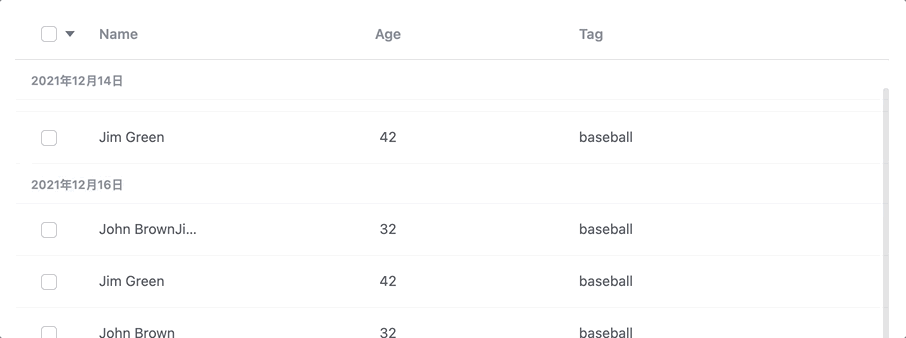
如上图,需要有下一个组头把上一个组头推上去的感觉。
那么这在布局上就要求真的有分组的概念。因为sticky的效果是需要下一个div将上一个div推走。
如果按照现在拍平的绘制逻辑,是无法做到的。
但是如果按照组的概念去绘制,那么虚拟上就会遇到问题。
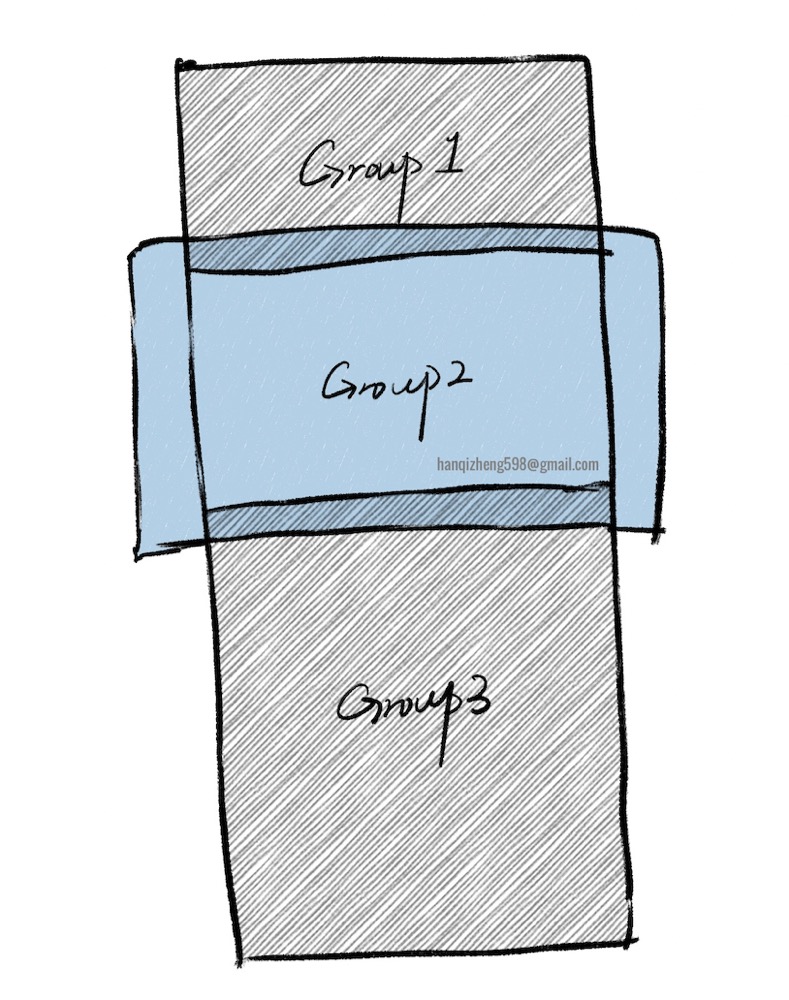
如果按组来进行虚拟,那么上图中Group3因为有一小部分进入了视口范围所以需要进行绘制。
但是如果Group3有100条数据,仅因为进入了1条数据,就要把额外的99条数据绘制一遍。
这个就是分组绘制导致的绑定绘制问题。
那么这这个时候就做了一个妥协。
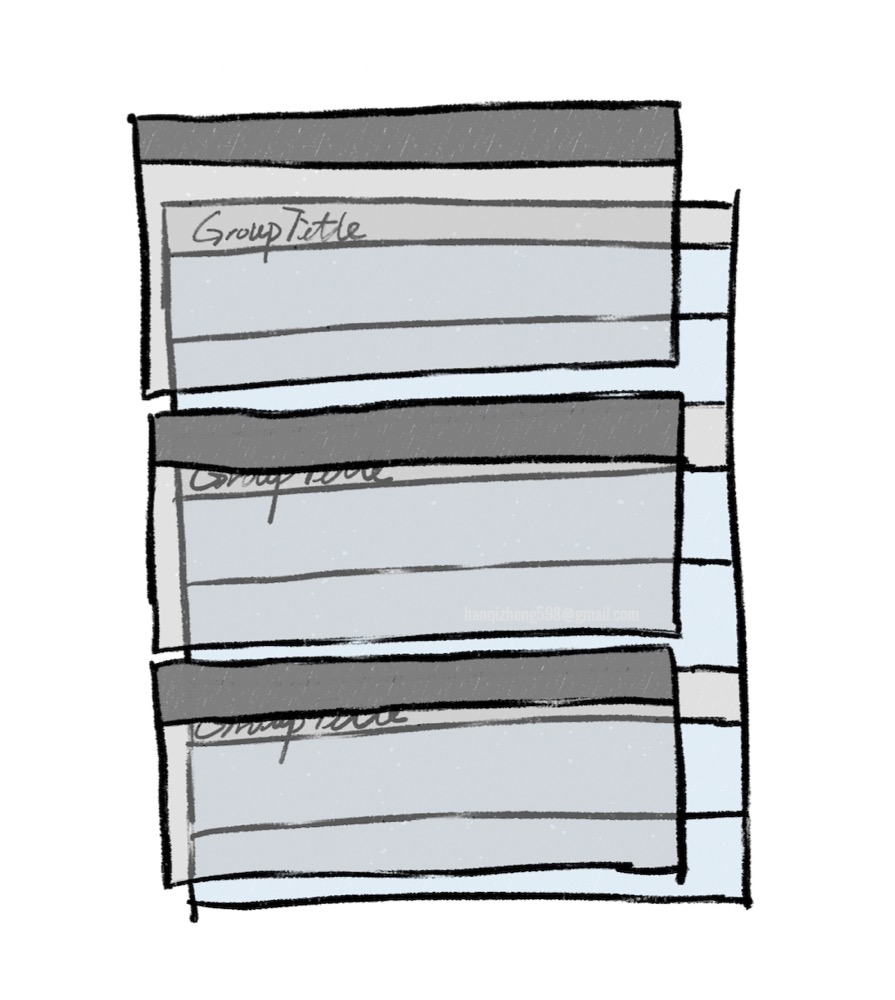
如上图,为了实现吸顶推动的效果,需要单独绘制一个GroupMask。里面仅是一个个按照组为单位的div。
这个是可以办到的,因为我们可以通过计算得到每个分组的高度
这样做,仅需要把GroupMask中的GroupTitle部分z-index调高,就能遮挡住实际的GroupTitle
然后就实现了分组的吸顶效果。
奇怪的收获与思考
这次分组功能算是NewTable近期添加的最大的功能了,随之也对写组件有了一些小小的思考。
不定高的虚拟
既然分组模式下,纵向的虚拟引入了offsetMap的概念进行绘制和虚拟,那么之前的行高自适应是不是也能引入虚拟呢??
行高自适应唯一和分组不同的地方就是第一次渲染。
行高自适应的第一次渲染需要渲染完成后再进行一次render才能保证绘制的正确。
如果抛开这个特点,应该是能虚拟的,但是如何做到第一次不虚拟,接下来的render虚拟仍然是一个问题。
对组件可扩展性的思考
分组功能的扩展其实非常考验NewTable代码的可扩展性。因为分组功能本身是和之前的绘制逻辑有一定的冲突。
而这次分组功能可以相对顺利的实现出来,不知道跟之前写的代码的可扩展性有无关系。
不能强求在最初开始编写代码时,就要想到未来可能发生的所有情况,这也是不可能的。但是如何让自己的代码能够思路清晰,便于维护,这真的是一门重要的必修课。
一种是可插拔,可配置,可扩展的组件。
一种是牵一发而动全身的组件。
如何去衡量这个度?如何去评判组件的好与坏?
这是需要我拥有一段不断去思考,去实践,去踩坑,去填坑的组件编写经历才能有所感悟的吧?